In the Internet’s early days, the homepage was king: Companies like Yahoo! fought to have the most relevant landing page for users. The hope was they’d make it their start page when opening their browser, and spend a long time on their sites, consuming content and features.
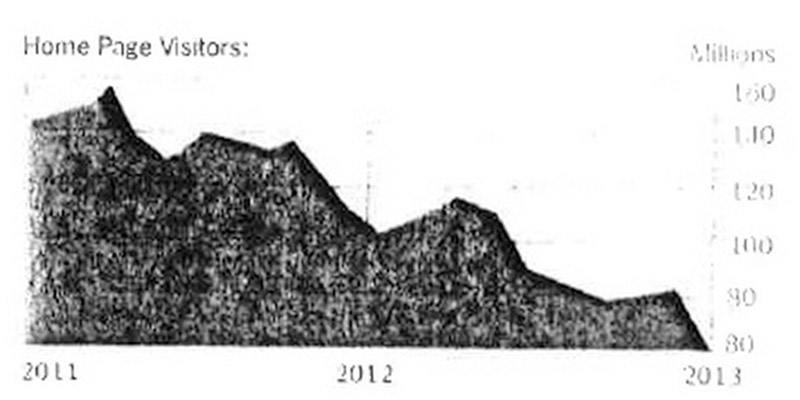
Since then, though, the assault on the homepage has been relentless. For awhile, it was RSS readers, allowing people to pump in their favorite content sources, and skip having to visit a bunch of random homepages. Now, of course, it’s social media, with people increasingly reading articles their friends or trusted media sources have shared on Twitter and Facebook. Indeed, The New York Times has seen their homepage traffic on its way down for years; the graphic above is their charted traffic, which has dropped by half in just 18 months.
This also creates a challenge for media organizations, as their sites are no longer as sticky. This leads to the proliferation of boxes listing social shares, editor’s picks, and of course, the ever-present services that state that “you may also like” other content. It’s another tough challenge for companies already trying to deal with revenue-rich print advertising being replaced by not-so-revenue-rich online advertising, and trying to get readers to pay more for content that a decade ago was ubiquitous and free, thanks to the publishers putting their sites (and archives) online at no charge.
Although I find myself not visiting homepages as much, I do have a few I check out, such as The Verge. Yet I also wonder why companies haven’t developed algorithms that can track what articles you’re reading, and, similar to the Amazon recommendation patterns, offer up other stories. Perhaps it’s because the news cycle is too quick, or not enough readership relative to Amazon’s massive audience, but it seems like an opportunity for someone to figure out.